Cassandra DB 간단하게 알아보기
![]() juneyr·
juneyr·
서론
최근에 cassandra DB 베이스의 저장소를 사용할 일이 생겼다. 해당 저장소를 사용해서 무사히 프로젝트는 마무리했으나.. 생각보다도 성능이 좋았다. 뭔데 이렇게 빠르게 삽입 / 조회 할 수 있는건지? 🤔 아주 작은 궁금증이 생겨서 궁금증이 해소될 정도만 알아보려고한다. NoSQL 에 대해서 전혀 정보가 없는 것도 가정한다.
Cassandra
이름의 유래는 당연히 그리스 로마신화 카산드라. (예언의 능력이 있지만 아무도 믿지 않았던) 그래서 로고도 반짝이는 눈 모양으로 추정.
기본은 NoSQL 의 분산 데이터베이스다. NoSql 자체가 가볍고, 비-관계성 (non-relational) 이고, 스키마 정의에 있어서 유연한 접근이 가능하다.
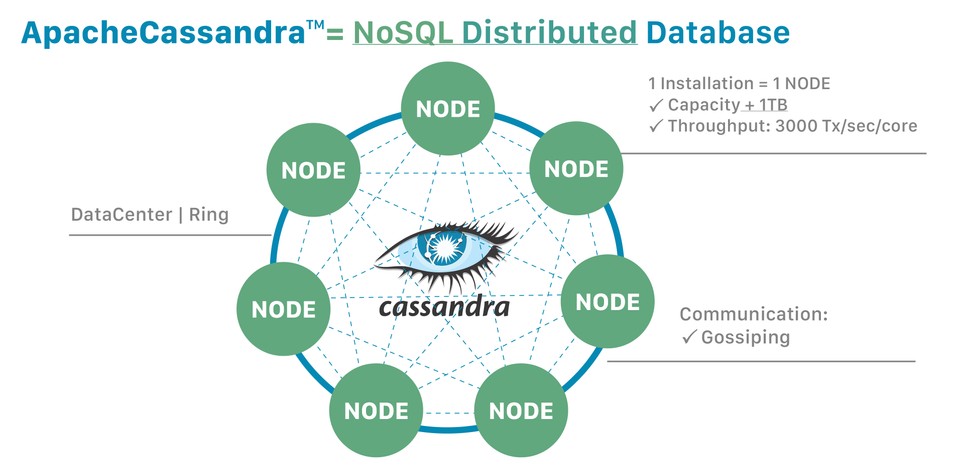
NoSQL 데이터베이스는 빠르고, ad-hoc 구조를 띌 수 있고, 볼륨이 크고 서로 종류가 다른 데이터에 대한 분석이 가능하다. 빅데이터의 등장 + 클라우드 환경에서 빠르게 규모 조절이 가능해야하는 (scalable) 과정에서는 장점으로 보인다!
카산드라의 큰 특징 중 하나는 데이터베이스가 분산되어있다는 점이다. 분산.. 하면 벌써
- 오 하나(혹은 일부) 죽어도 괜찮겠군?
- 대신에 분산된 데이터베이스들끼리 소통하려면 비용이 들겠군? 이건 어떻게 해결하려나? 하는 생각이 든다.
데이터베이스 분산의 장점을 좀더 풀어서 말해보자. 카산드라는 애플리케이션이 부하를 많이 받아도 쉽게 규모 조절이 가능하다. 분산했기때문에 데이터센터에서 물리적인 장애가 발생해도 데이터 손실을 방지할 수 있다. 그리고 개발자가 (아마도 개별 노드의) 읽기 / 쓰기 처리량도 조절할 수 있다는 장점을 카산드라는 말하고 있다.
'분산' ! 그러니, 유저가 실제로 하나의 데이터베이스로 카산드라를 인식하고 사용하도록 되어있지만 카산드라는 여러개의 머신에 나뉘어져있을 수 있다는 이야기가 된다. 물론, 하나의 노드(머신) 에만 사용할 수 있겠지만 그런 경우는 거의 없다.
노드 하나가 카산드라의 인스턴스로 구성되고, 이 여러 노드는 gossip 이라고 불리는 프로토콜을 통해서 소통한다. (위 이미지 참고) 카산드라는 또한 마스터가 없는 구조를 띄고 있어서 모든 노드가 같은 역할과 기능을 수행한다. 개념적으로는 ��노드가 클러스터 혹은 링 으로 구성된다고 이야기한다.
힘�을 원하는가 카산드라 유저여? 😈 노드를 추가해라...
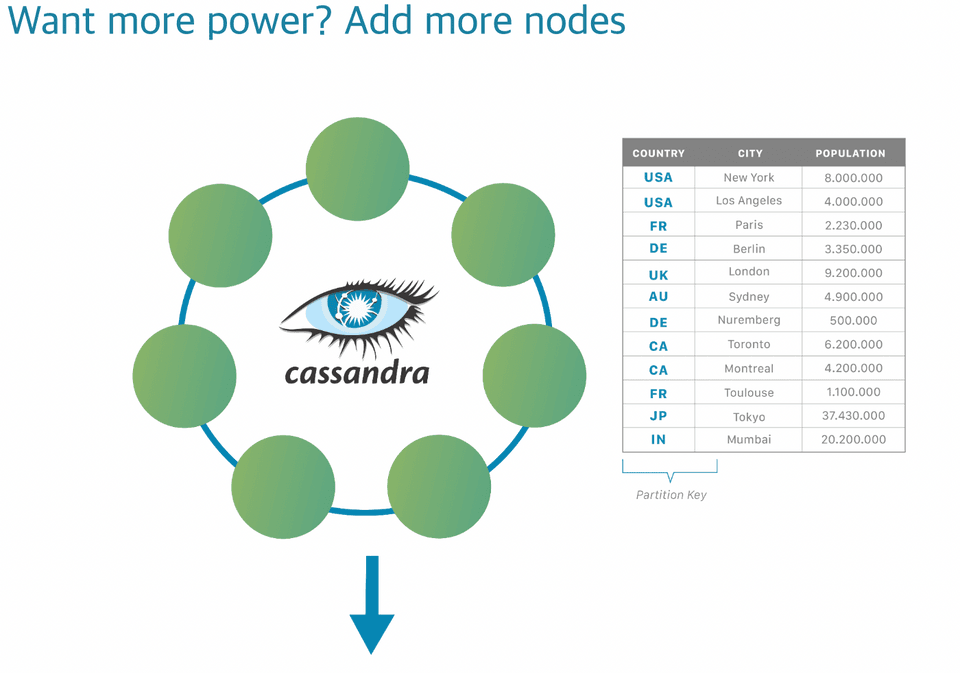
정말 이렇게 되어있어서 조금 웃었는데, 분산 아키텍처 형태를 띄는 카산드라는 노드가 많아질 수록 강해진다 (!) 카산드라의 강점 중 하나가 다운타임 없이 데이터베이스를 동적으로 추가하고 늘릴 수 있다는 점이다. (물론 줄일 수도 있고.) 오라클이나 MySQL 데이터베이스를 사용했을 때는 상상하기 어려운 강점이다. 그런 경우는, 더 많은 유저를 감당하기 위해서는 CPU / RAM / disk 추가등의 스케일 업을 고려하게 되니까! (이쪽이 돈이 많이 들기도 하고..)
반면 카산드라는 다룰 수 있는 데이터의 양을 늘리는데 아주 최적화되어있다. 흔한 스케일 아웃의 장점이지만, 상대적으로 저렴한 노드를 많이 추가함으로서 당연히 비용적 이득도 볼 수 있고.
카산드라의 파티션 🔖
카산드라는 분산 데이터베이스라서 당연히 데이터 자체도 자동적으로 분산된다. 이 기능은 파티션을 사용해서 이뤄지는데, 각 노드가 특정 토큰의 set을 가지고 있고, 카산드라가 이런 토큰의 범위를 기반으로 해서 데이�터를 나눈다.
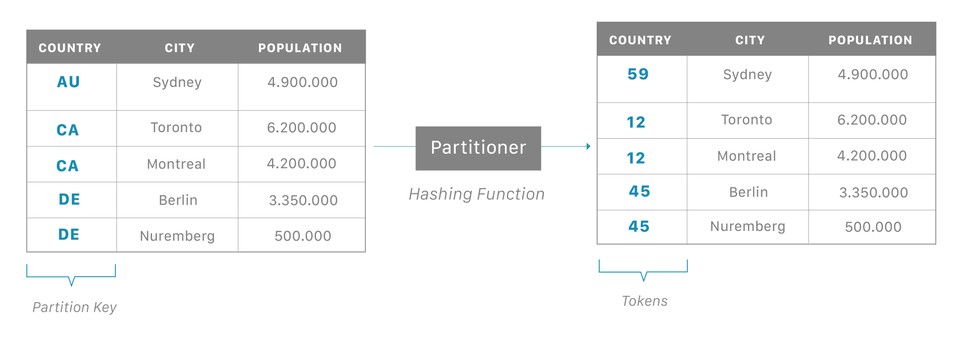
위 그림을 보면 좀더 이해가 될 것 같다. 원본데이터에 파티션 키가 될 항목이 하나 정해지면, 이 값을 파티셔너에 넣어서 카산드라 노드들이 갖고 있는 토큰 범위로 해싱해주고! 이 해싱 결과 (토큰 값)에 따라서 맞는 노드에 저장하는 방식이 될 것 같다.
데이터가 들어오면, 카산드라의 조정자 (coordinator, 물론 카산드라의 노드들은 다 동등해서 누구나 될 수 있음 😎) 는 해당 데이터를 특정 파티션 에 할당하는 일을 한다. 그리고 이제 실제로 저장을 하는데, 이 파티션이 어떤 토큰 범위에 해당하는지 다른 노드랑 소통하기 위해서 아까 말한 gossip 이라는 프로토콜을 사용한다. (노드 🫢: (수근수근))
파티션 59번에 넣는다고 하면, 조정자는 gossip 을 가지고 누가 59번 토큰을 갖고 있는지 확인한다. 확인이 되면 데이터를 그 노드로 전달한다. 전달받은 노드는 레플리카 노드(replica node)라고 불린다.
레플리카는 내게 안정감을 줘요..
하나의 데이터는 여러 노드에 복사가 될 수 있고, 당연히 이는 신뢰성을 높이고 장애 방지를 하게 된다. 카산드라는 RF(Replication factor) 라는 개념을 지원하는데, RF 는 얼마나 많은 복사본이 존재해야만 하는지 를 나타낸다. 예를 들어, RF=1 라면 하나의 레플리카에만 복사되었다는 뜻이다. 이 값을 RF=2로 올리면, 두번째 레플리카에도 저장되어야한다는 의미로 볼 수 있다.
카산드라는 데이터를 저장할 때 해당 데이터에 대한 '힌트' 개념도 저장을 해서, 만약 레플리카 하나가 다운되더라도 그 데이터를 다른 레플리카 어디에서 찾을 수 있는지 재빨리 찾아낸다. 이런 카산드라의 자가치유적 기능은 완전히 자동으로 진행된다.
레플리카를 사용하는 건 성능적 이점도 준다. 지리적 / 물리적으로 멀리 떨어진 노드에 하나만 저장되는 경우보다.. 여러개 저장된 노드 중 그나마 가까운 것에서 찾는게 좋겠지? 그래서다.
갑자기 CAP 정리 - 그리고 카산드라가 선택한 것
분산 시스템에서 나오는 CAP 정리. CAP 은 데이터베이스에서 트레이드 오프에 대한 논의를 하려는 경험적인 법칙으로 제안되었다. 그러니 엄밀한 이야기가 아니라는 이야기다. 데이터 중심 애플리케이션 설계 에서는 CAP 정리를 이렇게 정의한다.
CAP 은 때때로 일관성(Consistency), 가용성(Availability), 분단 내성(Partition tolerance) 라는 세 개 중 두 개를 고르라는 것으로 표현한다. 불행하게도 이런 식으로 생각하며 오해의 소지가 있다. (..중략..) 네트워크가 올바르게 동작할 때는 시스템이 일관성(선형성) 과 완전한 가용성 모두를 제공할 수 있다. 네트워크 결함이 생기면 선형성과 완전한 가용성 사이에서 선택해야한다. 따라서 CAP 은 네트워크 분단이 생겼을 때 일관성과 가용성 중 하나를 선택하라는 의미에 가깝다.
그리고 카산드라 공식 문서에서는 본인들의 데이터베이스를 여기에 위치했다고 표현한다.
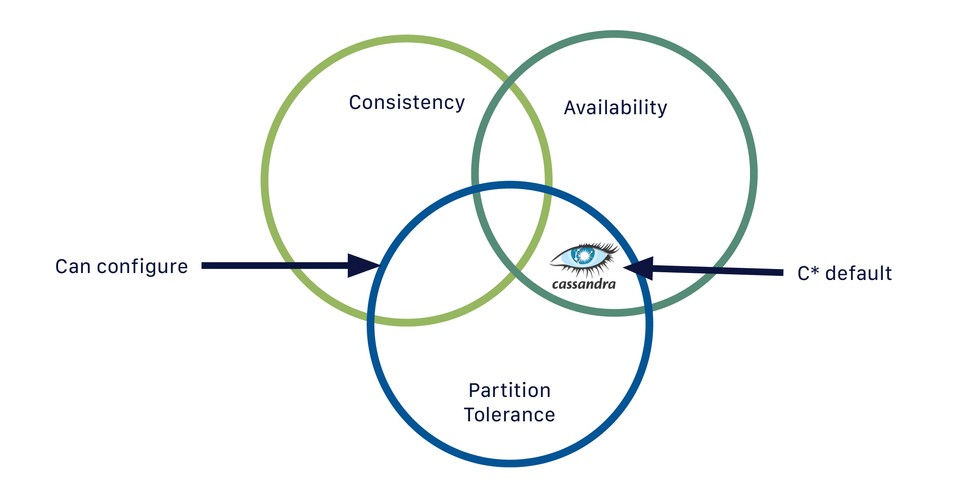
이런 입장에 따르면, 만약 네트워크 분단이 생기면 카산드라는 일관성(선형성) 보다는 고가용성을 선택한다. 공식 문서에서는 이를 AP(Available Partiion-tolerance) 로 표현하고, always on 이라고 말한다.
그러면서도, 쿼리 별로는 일관성을 설정할 수 있다고 말한다. 이러한 맥락에서 카산드라의 일관성 수준이라는 건, '이 읽기/쓰기 동작이 성공했어!' 라고 인정하는 노드의 갯수를 정할 수 있다는 것이다. 카산드라의 노드가 다 동등한 입장을 취하고 있다는 점을 생각하면 좀더 잘 이해된다. 하나의 쿼리 동작이 작동할 때 실제로 성공했는지 인정하는 위원회...의 정족수를 의미한다고 생각하면 어떨까. 예를 들어 RF=3인 경우, 3개의 레플리카에 복사된다. CL (Consistency Level, 일관성 수준)은 복사된 레플리카의 과반 (RF/2 + 1) 을 만족시켜야한다. 따라서 2개 이상이 '음 이 읽기/쓰기 동작은 올바른 것이고 성공했어' 라고 인정해야만! 동작이 성공한다고 전체적으로 인정해서 클라이언트에 반환한다는 것이다. 직관적으로 생각해봐도, 네트워크 결함이 생겼을 때도 과반의 수가 인정하는 동작만 성공으로 쳐서 데이터베이스 자체의 일관성을 유지할 수 있을 것 같다.
카산드라 docker 로 간단하게 깔아보고 입력해보기
나는 카-초보 이기때문에 quick start에 나와있는 대로 docker로 간단하게 깔아보기로 했다. 최근에 docker desktop에 많이 데여서 , docker desktop 의 무료 대안이라는 orbstack 을 설치했다. docker desktop 과 마찬가지로 로컬에 알아서 잘 docker 명령어가 설치된다.
로컬에 CQL 파일을 만든다. CQL(Cassandra Query Language) 는 SQL 과 비슷하기만 카산드라의 조인 없는 구조를 지원한다.
카산드라 quick start에 있는대로 아래 스크립트를 로컬에 만든다 (컨테이너 말고). 이 스크립트는 keyspace 를 만드는데, keyspace는 카산드라가 데이터를 복제하는 레이어이자, 데이터를 저장하는 테이블이다. 그리고 그 keyspace에 데이터를 집어넣는다.
아래를 실행하면, 만들어뒀던 카산드라 컨테이너에 CQL shell을 사용해서 방금 만든 스크립트를 저정한다.
여기서 갑자기 삽질.
가 connect가 안돼서 삽질을 많이했는데.. (직접 data.sql 을 마운팅하고, cqlsh(csql shell 에 우리가 띄워놨던 cassandra 를 연결하는)) 알고보니 CQL 버전이 3.4.6 이상이어야한다. 최신 카산드라 이미지에서 지원을 안하는듯. (2023.04.23 기준)

data.cql 를 적용하고 새로 cqlsh 을 띄워서 접속한다.
아래처럼 테이블 (keyspace) 를 조회해볼 수 있다.
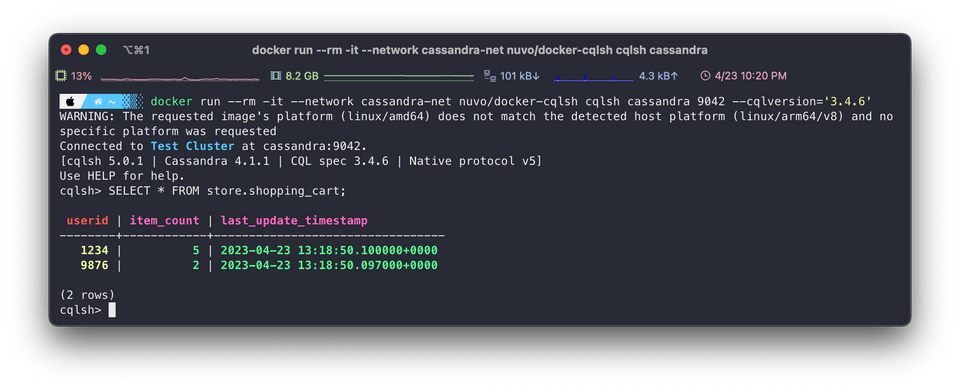
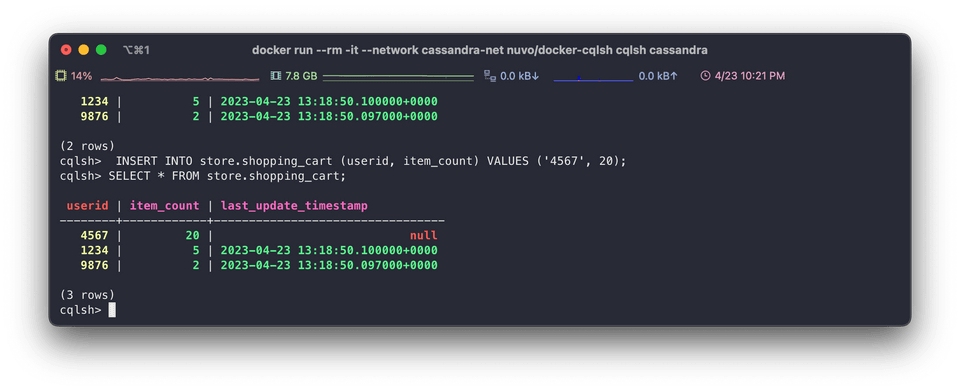
nosql 이면서도 table 형태로 조회되는게 인상 깊다. document 형태일 줄 알았는데.
참고
-
<데이터 중심 애플리케이션 설계>, p.334-335